 第18期 - LLM 迈向手机端!
第18期 - LLM 迈向手机端!

主打尊重隐私的搜索引擎 duckduckgo,也推出了 ai chat 服务,可以使用 chatgpt 或者 claude
Ai周刊:关注 Python、机器学习、深度学习、大模型等硬核技术
本期目录:
[toc]
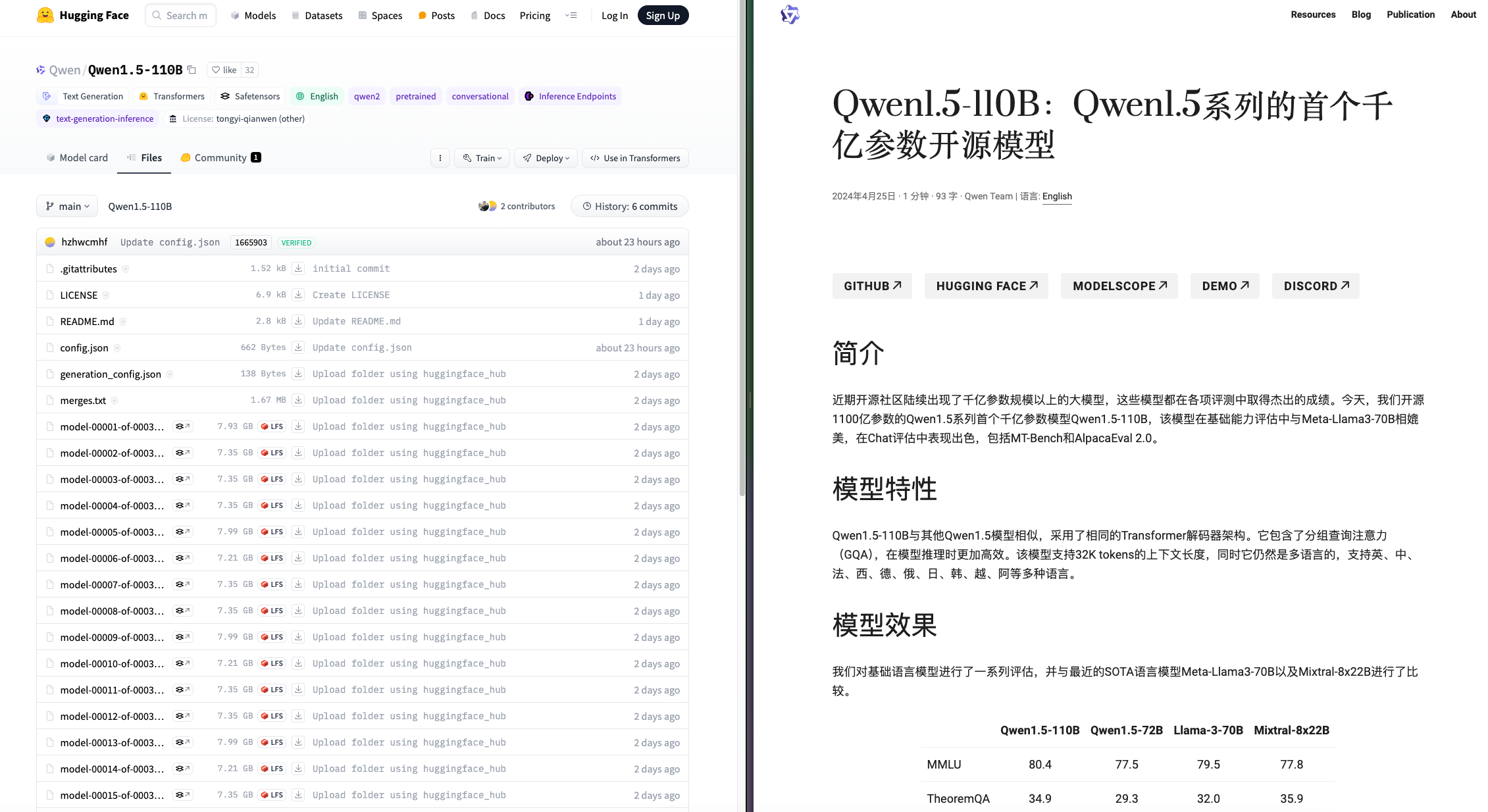
1、Qwen1.5-110B:Qwen1.5 系列的首个千亿参数开源模型
模型:https://huggingface.co/Qwen/Qwen1.5-110B/
博客:https://qwenlm.github.io/zh/blog/qwen1.5-110b/
Demo: https://huggingface.co/spaces/Qwen/Qwen1.5-110B-Chat-demo
阿里开源了 qwen1.5-110b 模型,模型在基础能力评估中与 Meta-Llama3-70B 相媲美,在 Chat 评估中表现出色,包括 MT-Bench 和 AlpacaEval 2.0。
支持高达 32k token 的上下文长度。
提供包括英语、中文、法语、西班牙语、日语、韩语、越南语等多种语言的多语言支持。
qwen2 也即将发布。
2、苹果开源了 openelm
论文:https://arxiv.org/abs/2404.14619
项目:https://github.com/apple/corenet
模型:https://huggingface.co/apple/OpenELM
苹果完全开源了 openelm 一系列模型,包括 270m、450m、1.1b 和 3b 四个规模的模型:
不仅包括模型权重和推理代码,还包括了在公开数据集上进行模型训练和评估的完整框架,涵盖训练日志、多个保存点和预训练设置。
还开源了 corenet:深度神经网络训练库:
使研究人员和工程师能够开发和训练各种标准及创新的小型和大型模型,适用于多种任务,如基础模型(例如,clip 和大语言模型(llm))、物体分类、检测以及语义分割。
openelm 采用按层分配参数的策略,有效提升了 transformer 模型各层的参数配置效率,显著提高模型精度。例如,在大约十亿参数的预算下,openelm 的准确率较 olmo 提升了 2.36%,且预训练所需的 token 数量减少了一半。

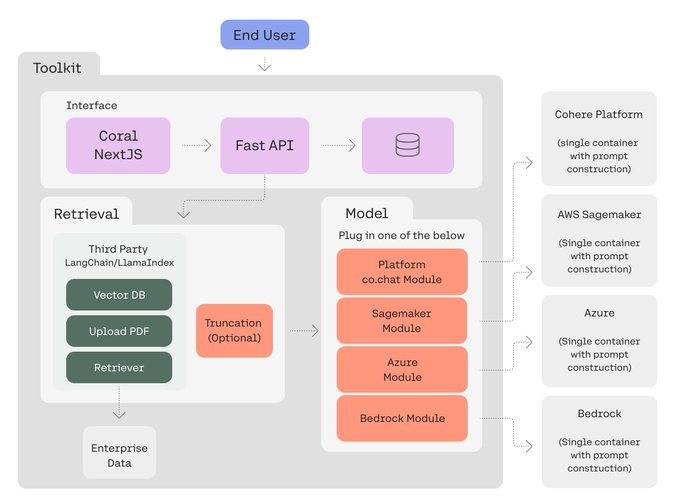
3、cohere 工具包:快速构建和部署 rag 应用
cohere 开源的工具包,用于开发 rag 应用,可以一键部署到微软 azure 上,也可以本地部署。
github: https://github.com/cohere-ai/cohere-toolkit
4、LLM 迈向手机端!微软发布 phi-3-mini 模型
论文:https://arxiv.org/abs/2404.14219 4k 模型:https://huggingface.co/microsoft/phi-3-mini-4k-instruct-onnx 128k 模型:https://huggingface.co/microsoft/phi-3-mini-128k-instruct-onnx
微软官方 phi-3 博客,很详细的阐释了 phi-3 参数选择的考虑和模型高质量的原因。
文中提到了 phi-3 在 slm 在端侧应用的场景和优势,认为 slm 和 llm 结合是更优解,也提到高质量数据在模型训练中的重要性。
1)参数:拥有 38 亿参数 2)性能:与 mixtral 8x7b 和 gpt-3.5 等模型同级 3)手机端部署:足够小,且针对手机端进行了优化 4)更多模型:还提供了 70 亿 和 140 亿 的 phi-3-small 和 phi-3-medium 模型,性能远超 phi-3-mini

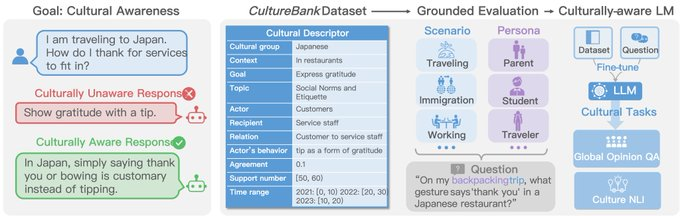
5、culturebank: 在线社区驱动的知识库
论文项目地址: https://culturebank.github.io
github 地址: https://github.com/salt-nlp/culturebank
culturebank 通过从 tiktok 和 reddit 等在线社区收集用户自述,构建了一个包含 1.2 万个文化描述符的数据库。与以往的文化知识资源不同,culturebank 不仅包含了多样的文化观点,还提供了具体的文化场景,以帮助对语言模型进行基于上下文的评估。对现有的大型语言模型(llms)进行文化意识评估,并微调了一个语言模型以提高其在文化相关任务上的表现。展示了如何将构建的管道应用于 reddit,证明了其可转移性。
文章还讨论了提高语言模型文化意识的未来方向,包括使用多样化的数据源、考虑文化内容的多个维度、进行深入的数据分析,以及在训练文化意识语言技术时考虑多轮对话设置和设计良好的训练范式。最后,文章提出了对文化数据的处理需要尊重个体和群体的尊严、隐私和文化敏感性,并呼吁社区共同努力,促进文化多样性和包容性。
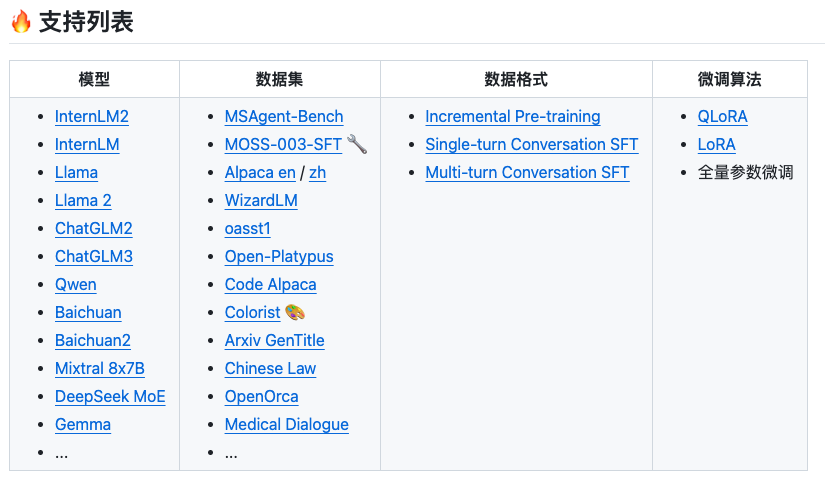
6、大模型微调工具 xtuner

地址:https://github.com/InternLM/xtuner
XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。
高效
- 支持大语言模型 LLM、多模态图文模型 VLM 的预训练及轻量级微调。XTuner 支持在 8GB 显存下微调 7B 模型,同时也支持多节点跨设备微调更大尺度模型(70B+)。
- 自动分发高性能算子(如 FlashAttention、Triton kernels 等)以加速训练吞吐。
- 兼容 DeepSpeed 🚀,轻松应用各种 ZeRO 训练优化策略。
灵活
- 支持多种大语言模型,包括但不限于 InternLM、Mixtral-8x7B、Llama 2、ChatGLM、Qwen、Baichuan。
- 支持多模态图文模型 LLaVA 的预训练与微调。利用 XTuner 训得模型 LLaVA-InternLM2-20B 表现优异。
- 精心设计的数据管道,兼容任意数据格式,开源数据或自定义数据皆可快速上手。
- 支持 QLoRA、LoRA、全量参数微调等多种微调算法,支撑用户根据具体需求作出最优选择。
全能
- 支持增量预训练、指令微调与 Agent 微调。
- 预定义众多开源对话模版,支持与开源或训练所得模型进行对话。
- 训练所得模型可无缝接入部署工具库 LMDeploy、大规模评测工具库 OpenCompass 及 VLMEvalKit。
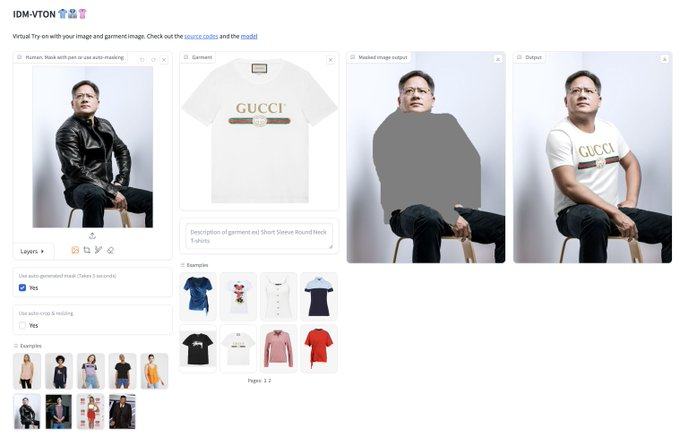
7、换衣应用在线体验
在线体验:https://huggingface.co/spaces/yisol/idm-vton
8、hf llama 3 中文模型列表
https://huggingface.co/models?pipeline_tag=text-generation&language=zh&sort=trending&search=llama+3
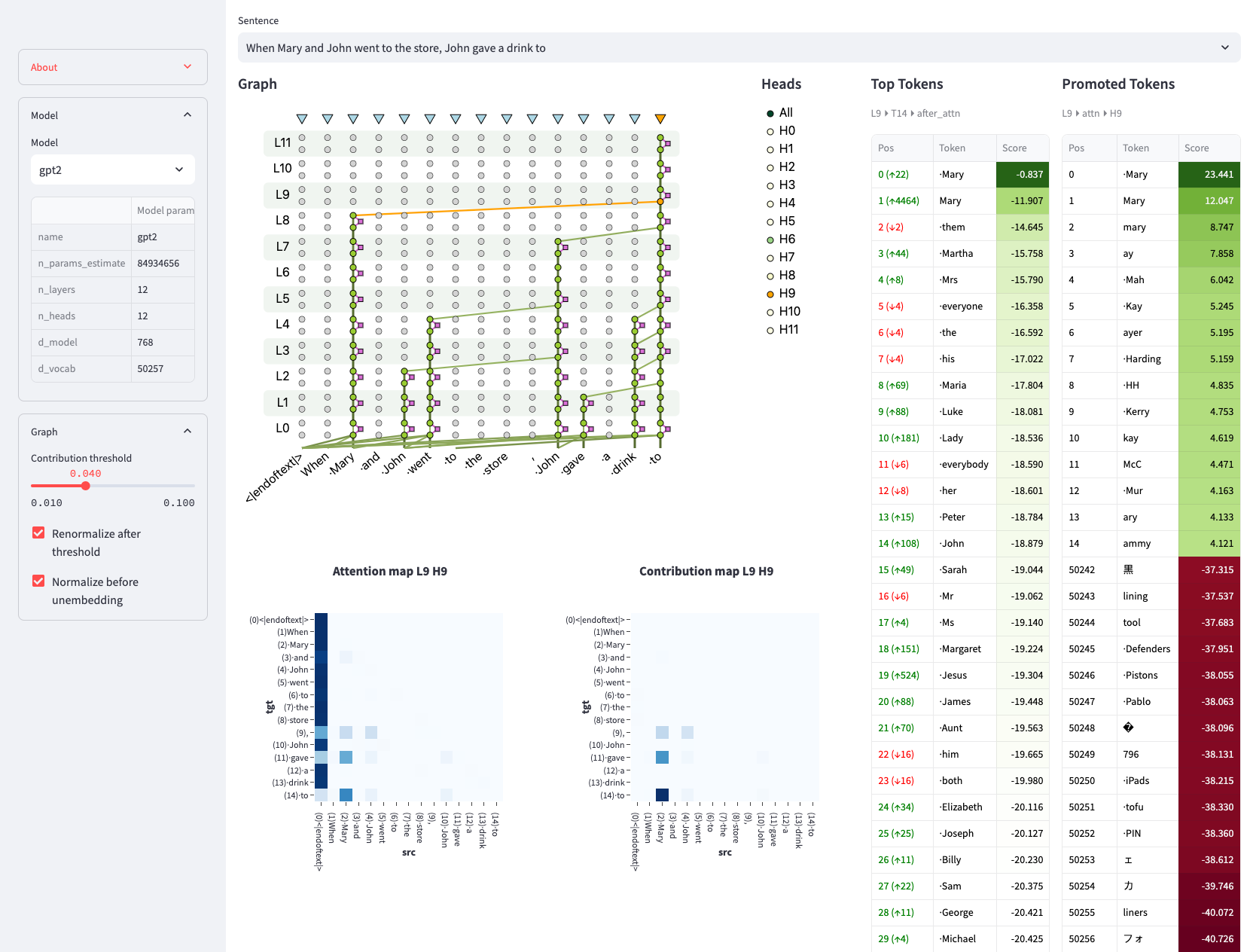
9、可视化 transfermor 模型的内部原理
facebook 发布了一个开源项目可以直接可视化 transfermor 模型的内部原理。作为直观理解 llm 基础原理很有帮助
https://github.com/facebookresearch/llm-transparency-tool
10、mistral 系列模型
mistral large:闭源,他家最强的模型,接近 gpt-4 mistral next:闭源,传言是新架构的模型 mistral medium:闭源,大致对应千问 1.5 72b 的能力 mixtral 8x22b:目前开源最佳 mistral small:即 mixtral 8x7b,最早的开源 moe 模型 mistral tiny:即 mistral 7b,7b 最佳基座
